
이전 포스팅에서 Internal Table의 종류와 선언 법에 대해 알아보았습니다.
이번에는 Internal Table을 읽고 쓰는 구문을 살펴보겠습니다.
데이터를 추가하는 구문 : APPEND, INSERT
데이터를 읽어오는 구문 : READ, LOOP
데이터를 수정하는 구문 : MODIFY
데이터를 삭제하는 구문 : DELETE
1) APPEND, INSERT
전 포스팅에서 Work Area를 책상에 비유했습니다. 작업을 마친 책상 위의 노트들을 책꽂이인 Internal Table에 꽂아 보겠습니다.
2021.06.24 - [ABAP] - [SAP ABAP 강좌 19] 변수 선언 및 Internal Table
[SAP ABAP 강좌 19] 변수 선언 및 Internal Table
안녕하세요. Slow Step입니다. 이번 포스팅에서는 변수를 선언하는 방법과 Internal Table이라는 SAP의 중요 개념을 살펴보겠습니다. 변수에 데이터 유형을 할당하는 구문으로 TYPE, LIKE, REF TO 등을 있습
stepwith.tistory.com
아래와 같이 선언된 Internal table이 있습니다.

APPEND 문을 사용하며 데이터는 Internal Table의 가장 아래 라인에 추가됩니다. 헤더 라인이 있는 경우와 없는 경우의 구문이 다를 수 있습니다.

추가적인 구문입니다.
APPEND LINES OF lt_stand1 TO lt_stand2.
INSERT LINES OF lt_stand1 INTO TABLE lt_stand2.
- 1번 테이블 데이터 전체를 2번에 추가할 때
APPEND LINES OF lt_stand1 FROM 1 TO 6 TO lt_stand2.
INSERT LINES OF lt_stand1 FROM 1 TO 6 INTO TABLE lt_stand2.
- 1번 데이블의 1~ 6 라인을 2번에 추가할 때
APPEND ls_stand2 TO lt_stand2 SORTED BY matnr .
- 흔히 구문을 보고 APPEND 후에 정렬을 해주는구나 생각하지만 틀린 것입니다.
해당 구문을 사용하려면 명시적인으로 어떤 종류의 테이블인지 선언이 필요하며, 그 초기 행수는 몇으로 한다는 것까지 정의하여야 사용 가능합니다. 그렇지 않으면 APPEND 문은 마치 없는 것처럼 무시됩니다.
DATA : lt_stand2 TYPE STANDARD TABLE OF mara INITIAL SIZE 4.
ls_stand2-matnr = '100000'. APPEND ls_stand2 TO lt_stand2.
ls_stand2-matnr = '100003'. APPEND ls_stand2 TO lt_stand2.
ls_stand2-matnr = '100005'. APPEND ls_stand2 TO lt_stand2.
ls_stand2-matnr = '100001'. APPEND ls_stand2 TO lt_stand2.
위처럼 명확히 테이블이라 선언을 하고 INITIAL SIZE 4 구문으로 초기값으로 몇 줄짜리 테이블이다 까지 지정합니다.
테이터를 정렬이 안된 채로 4개를 넣고 아래처럼 '100002'를 추가합니다.
ls_stand2-matnr = '100002'. APPEND ls_stand2 TO lt_stand2 SORTED BY matnr.
기대하는 결과는 아래이지만 이 구문은 그렇게 동작하지 않습니다.
'100000'
'100001'
'100002'
'100003'
'100005'
테이블 안을 디버깅으로 보면 아래처럼 데이터가 들어가 있습니다.

정렬은 오름차순이 아닌 내림차순입니다. 또한 입력되어 있는 데이터가 초기 지정한 라인수 보다 많으면 데이터를 추가하는 것이 아니라 한 줄을 없애고 들어갑니다. 있던 것이 뒤로 밀리거나 자신이 없어집니다.
데이터 추가 전에 정렬이 되어 있지 않으면 마지막 줄부터 비교하여 자신보다 작은 값의 바로 위로 자리를 잡습니다.
장황한 설명에 비해 잘 안 씁니다. 데이터 다 넣고 SORT 구문으로 정렬하는 것이 심적으로 이롭습니다.
2) COLLECT
상당히 유용한 기능입니다.
특정 사람이 받은 월급을 10년 누적으로 보고 싶다면 10년 치를 읽어서 + 계산을 하는 것이 아니라 COLLECT 구문으로 Internal Table에 값을 넣어서 누적을 구할 수 있습니다.
입력한 값 중 숫자 필드(I, P, F) 타입이 아닌 필드들에 대해 숫자 필드들이 누적되어 저장됩니다.

아래와 같이 사용하면 matnr = '100002'의 brgew 필드에는 100이 들어가 있습니다.
주의할 점)
APPEND등의 구문과 혼용을 피해야 합니다. 되도록 비어있는 테이블에 Collect 하고 후속처리를 하는 것이 좋습니다.
일종의 Hashed Table처럼 동작하게 되는데 APPEND, SORT 등으로 정렬을 바꾸면 많이 느려질 수 있습니다.
이미 데이터가 들어있는 테이블이라면 COLLECT 하려는 필드로 정렬하고 사용하는 것이 좋은 방법입니다.
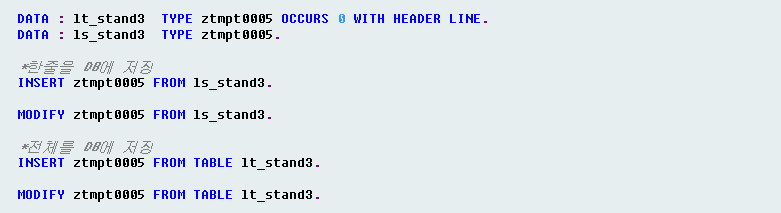
3) DB Table로의 데이터 저장
추가된 Internal Table데이터를 DB에 저장하는 구문도 많이 다르지 않습니다.
MODIFY = Update + Insert로 동일 키 데이터가 있으면 Update, 없으면 Insert를 수행해 줍니다.
Internal Table에 데이터를 추가하는 구문을 살펴보았습니다. 글이 길어져 Internal Table의 읽기, 수정, 삭제 다음 포스팅으로 넘기겠습니다.
긴 글 읽어주셔서 감사합니다.
'ABAP' 카테고리의 다른 글
| [SAP ABAP 강좌 22] Internal Table 활용3 - MODIFY, DELETE (0) | 2021.06.29 |
|---|---|
| [SAP ABAP 강좌 21] Internal Table 활용2 - READ, LOOP (0) | 2021.06.28 |
| [SAP ABAP 강좌 19] 변수 선언 및 Internal Table (0) | 2021.06.24 |
| [SAP ABAP 강좌 18] Data Type (0) | 2021.06.21 |
| [SAP ABAP 강좌 17] VIew Cluster (0) | 2021.06.01 |








최근댓글