
안녕하세요. Slow Step입니다. 이번 포스팅에서는 변수를 선언하는 방법과 Internal Table이라는 SAP의 중요 개념을 살펴보겠습니다.
변수에 데이터 유형을 할당하는 구문으로 TYPE, LIKE, REF TO 등을 있습니다. 어떨 때는 TYPE을 쓰고 어떨 때는 LIKE만 써야 해라는 접근은 버리고 마음껏 선언을 하고 디버깅을 잡아서 자신이 원하는 데로 선언되었는지 확인하는 게 좋을 것 같습니다.
프로그램을 접해본 분이라면 변수, 1차원 배열, 2차원 배열은 알고 계실 겁니다. 이것을 abap에 연결해 본다면 아래와 같이 비교가 될것입니다.
-. 하나의 값을 가지는 일반적인 변수
-. 1차원 배열을 Work Area 또는 Structure
-. 2차원 배열을 Internal Table
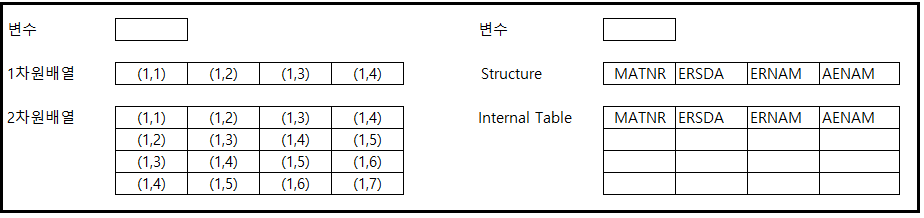
조금 다른 점은 데이터에 접근할때 배열명(1,1) 이런 주소가 아닌, 마치 DB Table처럼 필드명(LT_TABEL-MATNR 와같이)으로 데이터에 접근이 가능하다 정도가 다르겠습니다.
1) 변수의 선언
변수의 선언은 TYPE, LIKE, REF TO 등 오른쪽에 기술된 값의 기술적 유형 즉 Domain값과 동일한 형식의 변수가 선언됩니다.
아래의 선언은 모두 Char 18자리 변수를 선언한 것과 같은 효과가 나타납니다.

2) Local Structure, Work Area의 선언
하나의 변수가 아닌 변수의 1차원 모임을 선언하려면 Dictionay Objects(Table, Structure 등)를 참조 선언하거나 BEGIN OF ~ END OF의 구문을 사용합니다.
사실 변수의 모임을 딱히 부를 이름이 없어서 그 정의나 사용상의 특징을 보고 Work Area, Structure 등으로 부릅니다.
아래의 선언의 결과 값을 디버깅으로 보면 모두 같은 MAKT 테이블의 한 행과 동일한 변수가 보이게 됩니다.


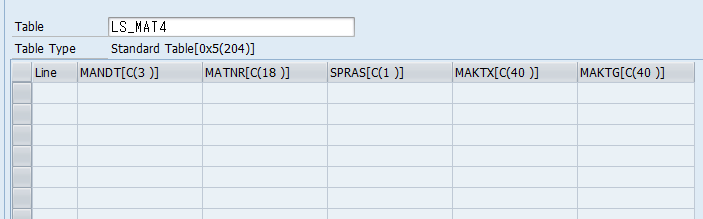
3) Internal Table의 선언
Internal Table을 2차원 배열로 보면 2) 번과 같은 1행짜리 데이터의 여러 줄 일 것입니다. 그럼 몇 줄이야를 정의하는 구문을 넣어서 여러 줄임을 표시하면 Internal Table로의 선언이 가능하지 않을까? 이때 OCCURS라는 구문을 사용합니다.
디버깅하여 그 구조를 보면 테이블 형식으로 선언되어 있음을 알 수 있습니다. OCCURS 뒤의 0은 데이터가 없는 초기값으로 사용할 메모리를 미리 할당하지 않음을 의미합니다. 10으로 하면 데이터를 추가하여 10으로 할당된 초기 메모리를 다 사용하면 10 단위로 추가 메모리를 확보하게 됩니다. (보통 1은 8KB를 의미)
Local Structure의 선언에 OCCURS 0 만 붙여서 선언해 봅시다. 디버깅을 해보면 바둑판 모양의 2차원 배열이 보입니다.

DATA 선언할Interal table명 TYPE or LIKE 참조 Object
위의 형식을 기본으로 본다면 참조 Object는 DB table, Internal Table, DB Structure, Local Structure, Types 등이 사용 가능합니다. 예로 아래 코드를 참조해봅시다.

같은 BEGIN OF ~ END OF의 구문을 사용하지만 Types와 Data로 선언한 것은 차이가 있습니다.
Data를 이용한 선언 : Work Area (Local Structure)를 만든 것으로 값을 넣고 사용 가능한 1차원 배열 변수를 만든 것.
Types를 이용한 선언 : Work Area (Local Structure) 나 Internal table을 만들 때 참조하기 위한 정의 만을 만들어둔 것으로 변수로서의 기능은 없습니다.
3-1) Internal Table의 종류
Internal Table의 종류를 좀 더 자세히 보자면, 전 포스팅인 Data Type에서 Generic ABAP Types에 기술한 데로
2021.06.21 - [ABAP] - [SAP ABAP 강좌 18] Data Type
Standard table, Sorted table, Hashed table이 있습니다. 필자는 Sorted table, Hashed table을 거의 사용하지 않았습니다. 대용량의 데이터 등 테스트를 통한 유의미한 속도 증가가 있다고 판단되면 사용하는 것도 좋겠습니다.
각각의 특징과 선언 방법을 살펴보겠습니다.
| Standard table | - 가장일반적인 테이블 - Index를 통해 데이타의 접근이 가능 - Non-unique key를 가진다 |
| Sorted table | - Key가 자동 정렬되어있는 테이블이다 - key, index로 데이타 접근이 가능 - Non-unique, unique key 둘다 사용가능 |
| Hashed table | - Hash 알고리즘을 이용한 Key로 행수에 상관없는 일정한 속도 데이타 접근가능 - Unique key를 가진다 - 200만건의 제한이 있다 |
기본적인 선언은 아래와 같다. LIKE 대신 TYPE을 사용해도 무방하다.

i) index로 데이터 접근이 가능하다?
여기서 Index는 무엇 일가 궁금할 수 있습니다. Standard와 Sorted는 index를 통해 데이터 접근이 가능하다고 합니다.
이 Index는 실제 DB(Olacle 같은...) 테이블의 읽기 속도를 빠르게 하기 위해 생성하는 Indexd와는 다른 말입니다.
간단하게 행 번호, 레코드 순번으로 이해하면 되겠습니다. Sorting으로 데이터의 순서가 바뀌면 다시 위에서 부터 1로 시작하여 index도 바뀐것입니다.
즉 데이터에 절대적인것이 아닌 정렬에 따라 유동적입니다.
Standard와 Sorted table은 몇 번째 Line을 읽어라와 같은 구문이 index를 이용해서 가능합니다.
ii) Non-unique, unique key?
DB 테이블 생성 시 Key를 지정하듯이 Sorted, Hashed Internal Table은 Key를 지정할 수 있습니다.
Sorted table은 Data를 추가 삭제하면 자동으로 Key로 정렬이 되며, Hashed는 추가된 행의 Key가 Hashe 알고리즘으로 블럭화 되어 key로 데이터행 바로 접근이 가능합니다.
Non-unique는 키가 동일한 데이터를 허용해야 하는 경우에 사용하고 unique 반대의 경우에 사용합니다. Hashed Table은 반드시 Unique 키를 가져야 합니다. 중복된 키로 1개 데이터에 바로 접근이 안 되겠죠.
iii) 속도는?
우리가 프로그램의 속도를 얘기할 때는 주로 읽는 속도를 말하게 됩니다. 전체 Key로 읽을 때의 경우를 보면
Hashed > Sorted > Standard 순이지만 데이 타량이 많지 않으면 Hashed와 Sorted는 비슷한 성능을 냅니다.
데이터를 추가하는 속도는 Standard > Hashed > Sorted가 됩니다.
3-2) Internal Table의 유형
Internal Table의 사용법은 가장 많이 사용하는 Standard Table을 기준으로 설명해보겠습니다. 특별한 코멘트가 없다면 Standard Table로 생각하고 보시면 됩니다.
자주 접하는 용어 중 Work Area, Structure가 있습니다. 두 개가 같은 의미로 사용된다 했는데 이 특징이 Internal Table관점에서의 이야기입니다.
책장을 데이터를 저장하는 Internal table이라 생각하고 차이를 본다면

좌측과 같은 일체형 책상이 있습니다. 책꽂이에서 책이나 노트를 빼서 붙어있는 책상에 펼쳐서 작업을 하고 다시 꽂아둡니다. 우측은 도서관이라 생각하고 책을 가져와 책상이 있는 곳에서 작업을 하고 다시 책장에 꽂아둡니다.
이 책장이 Internal table이라 했으니 작업장인 책상을 Work Area라 부르게 됩니다. Work Area는 책장에 붙어 있을 수도 있고 별개의 장소에 둘 수도 있습니다. 책장 한 줄의 책을 한꺼번에 뽑아 작업해야 한다는 가정하에 Work Area는 Internal table 한 줄과 동일한 모양으로 선언을 합니다. 그러다 보니 기술적으로 데이터 한 줄을 다루는 Structure와 같다 하여 Structure라고도 부릅니다. Dictionary Structure와 혼동이 있을 수 있으나 의미상 그렇다 하고 넘어가겠습니다.
이것을 프로그램 언어로 기술을 한다면

WITH HEADER LINE이라는 구문이 Wark Area 한 줄을 Internal Table에 붙여서 만들다는 구문입니다.
HEADER LINE 없이 생성한 아래 경우 Work Area를 따로 선언해 준 것이 LS_STAND2입니다.
어떻게 변수를 선언하던 그것이 Internal Table과 동일한 형식의 한 줄이라면 Work Area로 사용이 가능합니다.
HEADER LINE을 가진 Internal Table이라고 별도의 Work Area를 사용하면 안 되는 것도 아닙니다. 붙어있는 책상 말고 다른 책상에서 일을 하고 다시 책장에 꽂아도 문제가 없으니 까요.
아래 3가지 모두 동일한 기능을 할 수 있습니다.

단 HEADER LINE이 없는 Internal Table은 LIKE 구문만으로 Work Area 선언이 되지 않습니다.
DATA ls_stand2 LIKE lt_stand2. => 활성화 시 오류남.
LIKE는 Internal Table의 HEADER LINE과 동일한 한 줄을 만들려 하기 때문에 없다는 오류가 납니다. 이런 경우 데이터 라인 한 줄과 같게 만들라는 LIKE LINE OF라는 구문을 사용해야 합니다.
DATA ls_stand2 LIKE LINE OF lt_stand2.
주의)
CLASS를 사용한 개체 지향적 개발언어로 진화와 웹 개발과의 연동은 ABAP에도 피할 수 없는 대세인가 봅니다.
다른 언어나 웹 환경에서 보면 HEADER LINE과 Internal Table몸체는 같은 Name Space를 공유하여 개체구분이 명확하지가 않습니다. 지금은 HEADER LINE을 가진 Internal Table을 추천하지 않으며( 짜인 게 많다 보니 못쓰게는 못함) Work Area를 별도로 사용하기를 추천합니다. 그나마 CLASS 안에서는 아예 사용할 수 없습니다.
저는 코딩 양이 줄어드는 편함을 잊지 못하고 사용 중이나 고치려 노력 중입니다.
글이 길어지네요. ㅎ Internal Table 사용법은 다음 포스팅에 이어서 하겠습니다.
긴 글 읽어주셔서 감사합니다.
'ABAP' 카테고리의 다른 글
| [SAP ABAP 강좌 21] Internal Table 활용2 - READ, LOOP (0) | 2021.06.28 |
|---|---|
| [SAP ABAP 강좌 20] Internal Table 활용1 - APPEND,COLLECT (0) | 2021.06.25 |
| [SAP ABAP 강좌 18] Data Type (0) | 2021.06.21 |
| [SAP ABAP 강좌 17] VIew Cluster (0) | 2021.06.01 |
| [SAP ABAP 강좌 16] Maintenance View - Events 예제 (0) | 2021.05.31 |








최근댓글